Hash Collisions with Python
Last semester I took a computer security class at my university (the University of Oklahoma), my first computer secutiry class of any kind. I was shocked to find out just how much goes into securing a modern computer that we just take for granted. One of the most interesting assignments that we got to do for the class was to see how many bits of hash collisions on the SHA-3 hash algorithm that we could generate given a starting string. I managed to get 64 bits of collisions and I’d love to share the method I did so. My professor gave us a hint and linked us to the Wikipedia page on cycle detection. For the longest time I was baffled on how to take this hint given and convert it to a solution to our problem.
After reading through the page a few times, I realized that I had to change my viewpoint: the goal of this problem was to find two string solutions that hash to the same first x bits that have our constraints that they start with the same substring (in this case our school ID). When I finally started looking at it like a linked list problem I saw how the cycle detection algorithm could be used to easily find collisions, just like in the linked list cycle problems I’d been studying for interviews.
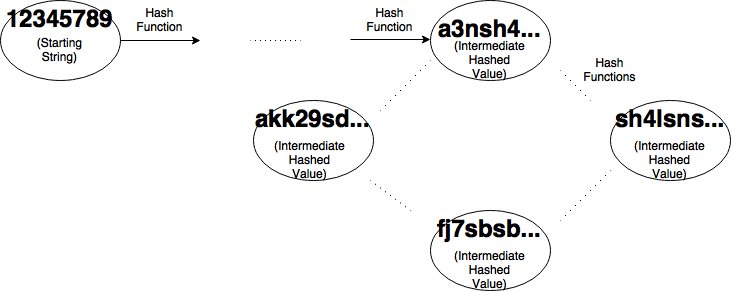
After we visualize the problem as a graph we get something like the image above. Each node except the first represents a intermediate value that we get by hashing the previous node. Each edge represents the application of the hashing algorithm, in this case SHA-3. At each running of the algorithm, we will choose how many bits we want in our output strings to match. Then our algorithm will create two pointers, a slow pointer and a fast pointer both starting at my initial value (in my case my ID number) as shown below.
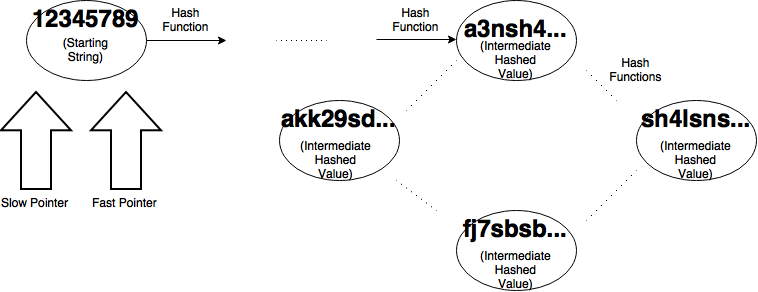
For our slow pointer, we progress one node at a time by hashing our starting value once. Our fast pointer will progress two nodes by hashing the start value and hashing that value. Then we check and see if the first x bits of our outputs are equal. If they aren’t we continue doing this until they are. If they are we have found a cycle.
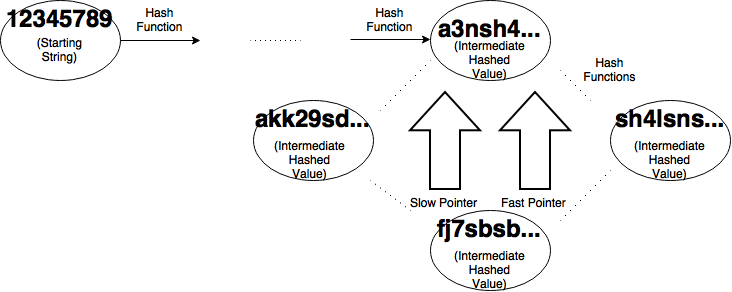
Eventually there will be two strings that have their first x bits equal to each other. Since we can’t unhash the values to get their start string, we have to calculate them by “rewinding”.
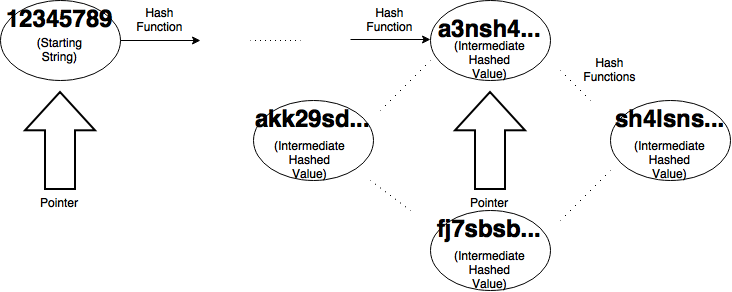
To do this, we take one of the pointers and move it back to the initial value. We leave the other one on the collision and set them both to move one node at a time. If you let them run until they collide again, saving the value before they hash, we can easily get our collision in n steps where n is the size of the cycle. This will be much less time than the initial collision finding.
This technique allows us to find hash collisions easily in SHA-3. Part of the assignment was to demonstrate to us how difficult it is to find collisions in this best hash function. I definitely found that out, with only 64 bits of collisions taking over 12 hours to run on my quad-core desktop machine. Overall I found the assignment fascinating and am glad to have taken the class!
Code: